

1. 프로젝트 개요
- 공모전명: 고용노동 공공데이터 활용 공모전
- 기간: 2025.03.10 ~ 2025.05.15 (약 2개월)
- 팀 구성: 처음에는 4명이었으나 중간에 1명이 탈퇴해 3명이서 진행
- 내 역할: 데이터 전처리(단위 통일, 파생변수 생성), 시계열 분석(SARIMA, STL), 데이터 시각화
2. 문제 정의
이번 공모전 주제로 잡은 것은 노동시장에서의 ‘반복 실업 루프’ 탐지 및 예방 시스템 개발이었다.
- 반복 실업: 고용과 실업이 주기적으로 반복되는 현상
- 문제점: 짧은 실업급여 제도 남용, 노동시장 구조 불안정 심화
- 목표: 반복 실업 위험이 높은 집단을 탐지하고, 예측 가능한 모델 구축
3. 데이터 수집 및 처리
데이터 출처
- 공공데이터 포털, KOSIS 국가통계포털 등
- 주요 데이터: 고용보험통계 (산업별/연령별/성별 피보험자격 신규취득자 및 상실자 현황), 구직급여 신청자 수, 근로실태조사, 임금 및 근로시간 통계 등
팀 작업 방식
- 각자가 맡은 데이터를 전처리 후 병합하는 방식
- 나는 ‘산업/연령/성별별 평균 임금 및 평균 근로시간’ 파생 변수 생성, 단위 통일, 시계열 분석을 맡음
내 데이터 전처리 주요 내용
- 불필요한 컬럼 제거: 정규 근로자만 포함, 결측치 및 불완전 데이터 제거
- 단위 통일: 임금(천원 단위), 근로시간(시간 단위)로 통일
- 데이터 통합: 2020년~2023년 월별 데이터 병합 및 정렬
- 파생 변수 생성:
- 산업/연령/성별 평균 임금 및 근로시간 계산
- 예를 들어, 20대 농업 여성 평균 임금은 산업(60%), 연령(20%), 성별(20%) 가중치를 둔 가중평균으로 산출
- 가중치 선정 이유:
- 단순 평균은 비현실적
- 베이지안 평균은 표본수가 없으므로 불가능
- 산업 60%, 연령 20%, 성별 20% 비중 적용
4. 데이터 탐색(EDA) 및 인사이트

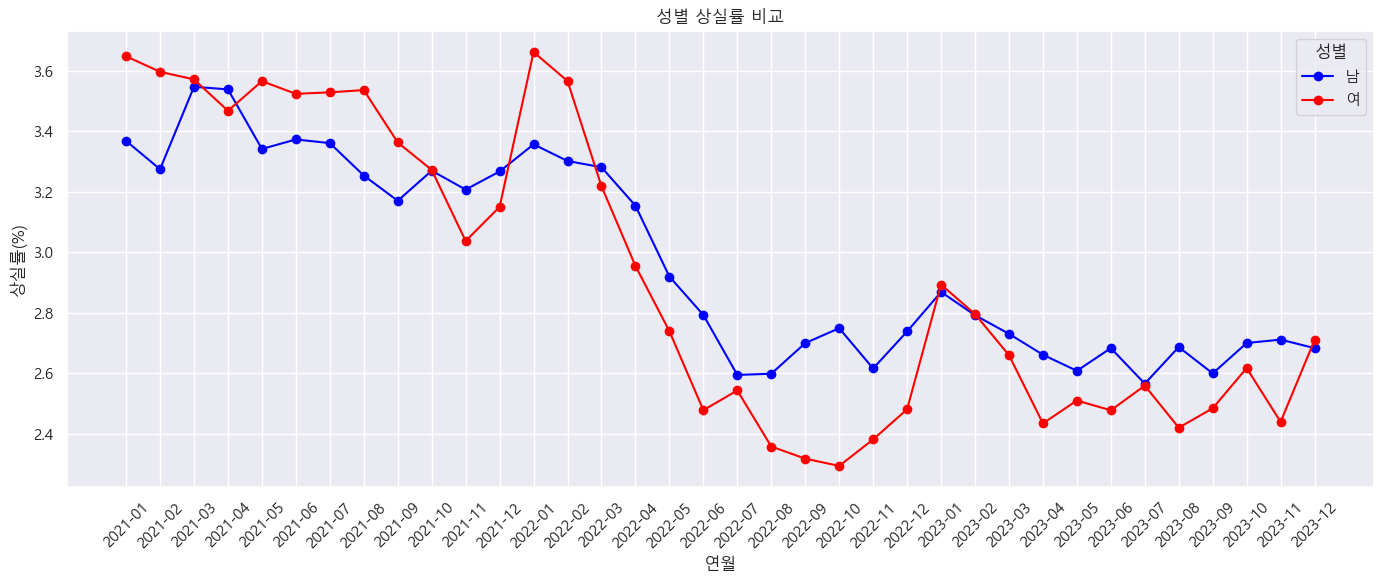
- 여성은 남성에 비해 전반적으로 재취득률이 더 높은 추세를 보이며, 특히 연초(1~3월)에 그 차이가 뚜렷하게 나타난다. 다만, 같은 시기에 상실률도 함께 상승하다가 낮아지는 경향을 보인다.

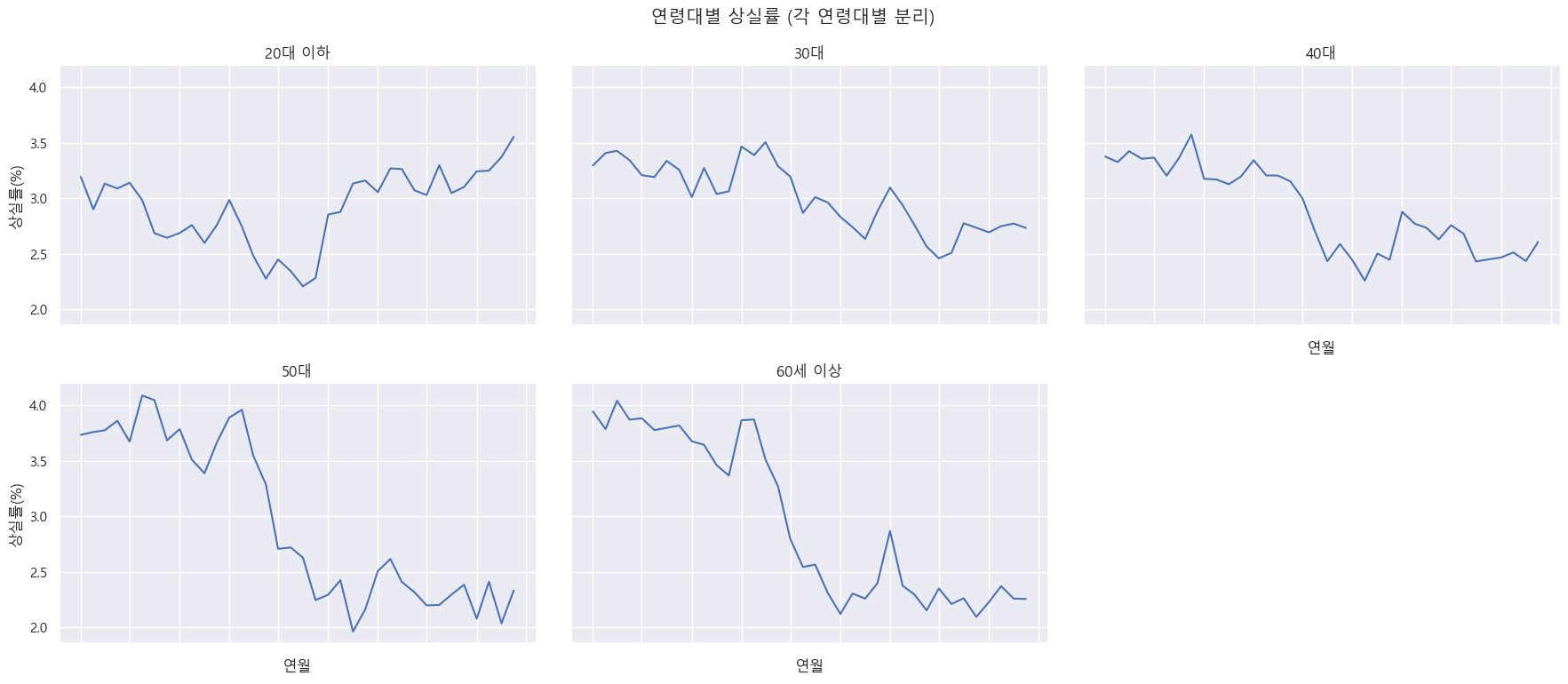
- 20대는 실직 이후 재취업으로 돌아가는 비율이 낮고, 상실률은 가장 높은 집단으로 나타났다. 이는 반복 실업 루프의 고위험군으로 해석 가능하다. 반대로 50대 이상은 재취득률이 오히려 높은 수준이며, 상실률도 낮아 고용 유지 안정성이 높은 집단으로 보인다.
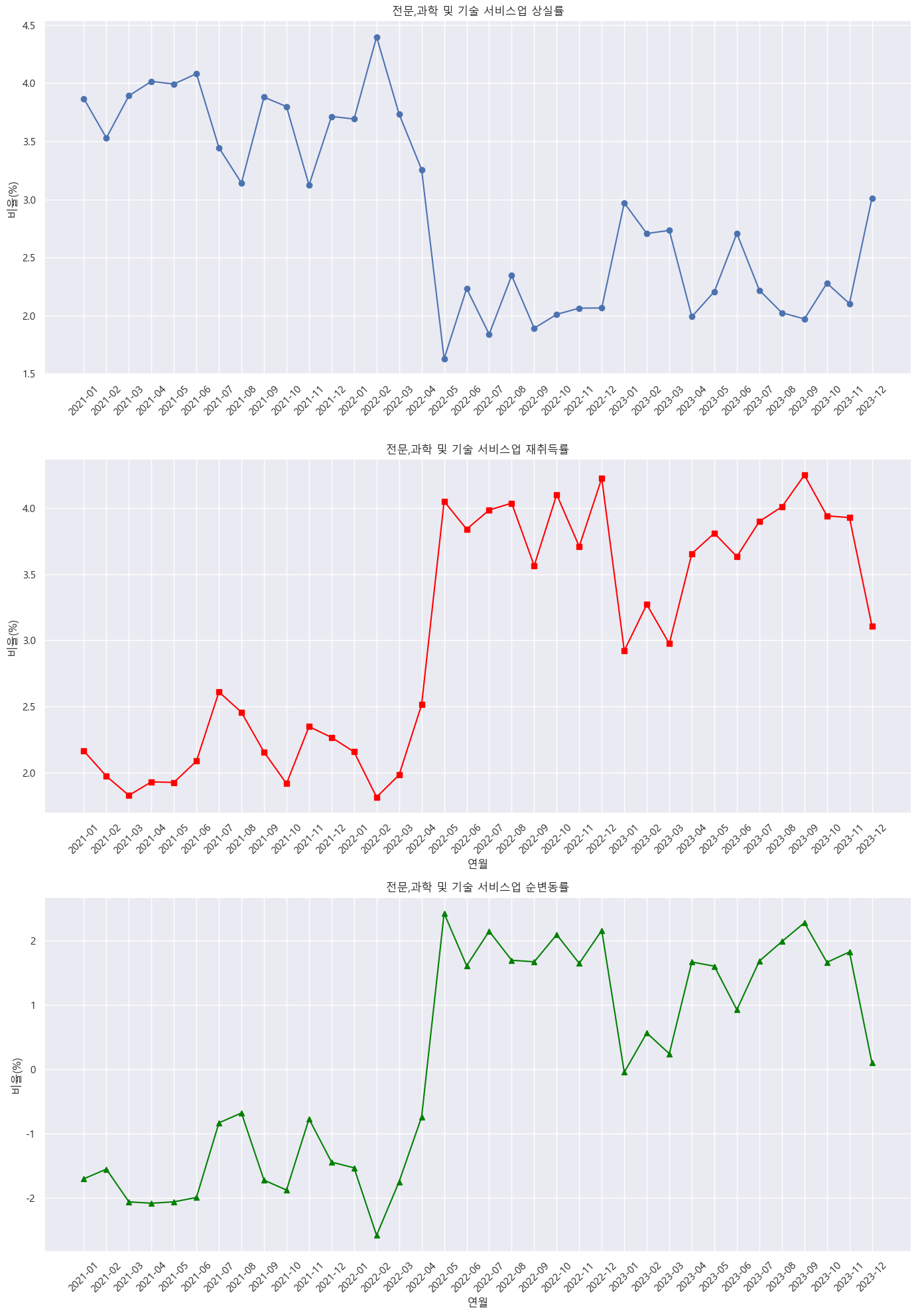

- 산업별 차이:
- 전문·과학 및 기술 서비스업은 코로나 이후 상실률 감소, 재취득률 상승 추세
- 제조업은 연초에 상실률 급증, 재취득률은 낮은 편
5. 시계열 분석 및 모델링
- 내 역할: SARIMA 모델을 활용한 시계열 예측 및 STL 분해 적용
- 목적: 고용 불안정성의 시간적 패턴 파악 및 주요 지표 예측
- 팀 내 모델링: 다른 팀원이 군집분석과 랜덤포레스트로 반복실업 위험 예측 모델 개발
먼저 상실률 데이터의 구조를 파악하기 위해 STL 분해를 진행하였다.

그 결과 추세와 계절성이 동시에 존재하였고 두 가지의 특징을 모두 모델링 할 수 있는 SARIMA가 좋다고 판단하였다.
model = SARIMAX(ts, order=(1,1,1), seasonal_order=(1,1,1,12))
- 모델 설정: 기본적인 (1,1,1)(1,1,1,12) 구성 사용
- 예측 구간: 향후 12개월(steps=12)

RMSE는 0.9564로 나타났고 0.96%의 오차를 보인다는 의미이다.
전체 상실률이 2~4% 범위에서 움직이는 고려할 때, 이는 주요 추세와 계절적 패턴을 포착하기에 의미 있는 정확도라고 판단

과거 데이터와 마찬가지로 연초에 상실률이 급격히 상승하고 갈수록 하락하는 계절적 패턴을 보여주다가 예츠 구간에서는 상실률이 다시 완만히 상승세로 반전 될 가능성이 나타났습니다.
아래는 팀원분이 한 군집분석과 랜덤포레스트로 만든 예측 모델 개발


6. 협업 및 문제점
1. 팀원 A가 나한테 데이터를 주고 내가 전처리(파생변수 생성 및 단위통일)을 해야했는데 중간중간에 잠수를 타버리고, 내가 원하는 컬럼으로 통일하지 않아서 일처리가 늦었다.
-> 내가 일일히 컬럼 수정 및 전처리를 다시 하였다. 이번 협업을 통해 '킥오프 미팅 + 업무 요구사항 명문화'의 중요성을 절실히 체감했다. 단순 회의나 구두 요청만으로는 오해가 생기기 쉬우며,
누가 언제까지 어떤 컬럼을 어떤 형태로 가공해 전달해야 하는지까지 문서화해야 이후 병합/분석에서 불필요한 리워크를 줄일 수 있다.
2. 데이터 관리의 중요성
-> 이번에는 각 팀원끼리 필요한 데이터가 달라서 각자 관리했지만, 전처리 및 병합을 이루고 나니 나중돼서는 언제 어떤 데이터를 받았으며, 어디에 보관되어 있는지 정확히 파악이 힘들었다.
데이터를 정리 할 땐 그 때마다 방법을 고안하려 하지말고, 규칙을 정해서 기계적으로 해야할거 같다.
최소한의 방법으론
- 폴더 구조 템플릿화 : 받은 파일, 이를 통대로 정리한 파일, 분석 스크립트 등으로 폴더 나누기
- 파일 명명 규칙 설정 : 팡리 업데이트 날짜나 버전 중심으로 파일명을 정하고, 어느 파일이 최신 파일인지 한눈에 알 수 있도록 규칙만들기
- 작업 중간에 생성된 파일 , 분석에 사용한 최종 파일은 별도로 정리 : 분석 재현이 언제든 가능하도록 해두기
7. 마무리 및 회고
- 이번 공모전은 처음으로 팀 프로젝트를 경험하며 데이터분석가 역할을 실전에서 체험할 수 있었던 좋은 기회였다
- 데이터 단위 통일, 파생 변수 설계 등 기초적인 데이터 전처리 역량을 키울 수 있었다
- 협업과 데이터 관리의 중요성을 절실히 느꼈고, 앞으로 체계적 프로젝트 관리 능력을 키우는 게 필요함을 깨달았다
- 다음 공모전에서는 더 명확한 역할 분담과 일정 관리, 그리고 분석 결과 시각화 및 스토리텔링을 강화할 계획
'기타' 카테고리의 다른 글
| [GDSC] 윈터해커톤 후기 (0) | 2023.03.29 |
|---|---|
| [GDSC] 놀러와요 해커톤 참여 후기 (0) | 2022.11.18 |

