https://dhlottery.co.kr/gameResult.do?method=byWin
로또6/45 - 회차별 당첨번호
1015회 당첨결과 (2022년 05월 14일 추첨) 당첨번호 14 23 31 33 37 40 1015회 순위별 등위별 총 당첨금액, 당첨게임 수, 1게임당 당첨금액, 당첨기준, 비고 안내 순위 등위별 총 당첨금액 당첨게임 수 1게임
dhlottery.co.kr
◆ 라이브러리 BeautifulSoup
BeautifulSoup는 HTML 태그를 효율적으로 탐색하고, 원하는 정보를 손쉽게 추출하기 위한 라이브러리이다.
다른 라이브러리로도 충분히 추출할 수 있지만 매우 편리하다는 장점이 있다.
◆ BeautifulSoup의 필요성
https://zzuzzu-99.tistory.com/22
[웹 크롤링] 6. 정적 크롤링(1)
◆ 크롤링 대상 사이트 살펴보기 크롤링을 할 때는 꼭 해당 웹 사이트를 살펴봐야한다. 바로 정적 크롤링 / 동적 크롤링 중 어떤 것이 적합할지 정해야 하기 때문이다. 로또 당첨 번호의 경우는
zzuzzu-99.tistory.com
지난번에 requests 만으로도 HTML 코드를 불러왔었는데 그 때는
필요한 정보뿐만 아니라 원하지 않는 정보도 포함되어 있었다.
(HTML의 태그와 선택자를 사용해 데이터를 추출한 것은 아님)
HTML 코드를 문자열 타입으로 처리해 HTML을 텍스트로 출력 했을 뿐
BeautifulSoup 라이브러리는 문자열을 실제 HTML 코드로 변환해 주는 것이다.
◆ BeautifulSoup 사용하기
1. BeautifulSoup 객체 생성
문자열 타입인 raw.text.를, 데이터의 타입은 html이므로 'html.parser'를 넣어준다.
클래스의 객체를 생성하면서, 문자열을 HTML로 변환해 준다고 생각
import requests
import bs4
URL = 'https://dhlottery.co.kr/gameResult.do?method=byWin'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')둘의 변수 타입이 다르다.
raw.text = <class 'str'>
html.parser = <class 'bs4.BeautifulSoup'>
2. find 함수
BeautifulSoup 객체를 생성했다면 find와 find_all 함수를 사용할 수 있다.
find 함수는 인자로 받은 태그와 선택자와 처음 일치하는 데이터를 리턴한다.
import requests
import bs4
URL = 'https://dhlottery.co.kr/gameResult.do?method=byWin'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
t = html.find('div',{'class':'nums'})
print(t)#출력결과

find함수의 인자로 'div'와 '{class':'nums'}를 넣어줬다.
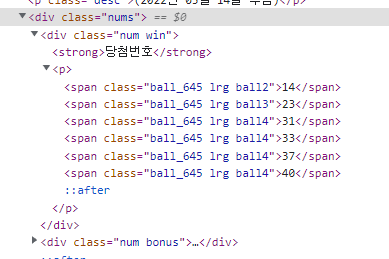
파악했던 로또 번호 데이터에서 번호를 모두 포함하고 있는 태그는
<div class = 'nums'>이다.
따라서 find함수의 첫번째 인자로 태그를, 두번째 인자로 선택자를 넣어주어
내가 원하던 태그의 내용만 출력한 것이다,
#1. 태그만 사용하는 경우
html.find('dic')
#2 선택자만 사용하는 경우
html.find(id = 'example')
html.find(a = {'id':'example'})
#3 태그 이름과 선택자 정보 모두 사용하는 경우
html.find('div',{'id':'example'})
3
함수 find_all()
find 함수는 태그와 선택자가 일치하는 가장 첫 태그를 받아왔다면
find_all 함수는 일치하는 모든 데이터를 리스트 형태로 리턴한다.
import requests
import bs4
URL = 'https://dhlottery.co.kr/gameResult.do?method=byWin'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
t = html.find('div',{'class':'nums'})
luck_nums =t.find_all('span',{'class':'ball_645'})
for num in luck_nums:
print(num)#출력 결과

find 함수를 사용해 찾았던 데이터에서, class가 ball_645인 span 태그들을 모두 받아오는 코드이다,

4. 텍스트 데이터 추출
받아온 태그에서
num 대신 num.text를 출력해 주면 된다.
import requests
import bs4
URL = 'https://dhlottery.co.kr/gameResult.do?method=byWin'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
t = html.find('div',{'class':'nums'})
luck_nums =t.find_all('span',{'class':'ball_645'})
for num in luck_nums:
print('당첨번호 :', num.text)#출력 결과
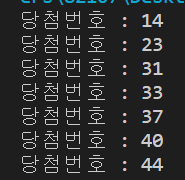
최종 코드
import requests
import bs4
URL = 'https://dhlottery.co.kr/gameResult.do?method=byWin'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
t = html.find('div',{'class':'nums'})
luck_nums =t.find_all('span',{'class':'ball_645'})
for num in luck_nums[:-1]:
print('당첨번호 :', num.text)
print('보너스 번호:' ,luck_nums[-1].text)
#출력 결과

★정리하기★
✔ 정적 크롤링 라이브러리 BeautifulSoup
- HTML 문서를 탐색해서 원하는 부분만 뽑아주는 라이브러리
- 실제 HTML 코드로 변환해준다.
✔ BeautifulSoup의 주요 함수
- BeautifulSoup()
- find_all()
- find()
'[python] > 웹 크롤링' 카테고리의 다른 글
| [웹 크롤링] 네이버 주식 상하한가 종목 크롤링 (0) | 2022.06.26 |
|---|---|
| [웹 크롤링] 8. 정적크롤링(3) (0) | 2022.05.22 |
| [웹 크롤링] 6. 정적 크롤링(1) (0) | 2022.05.18 |
| [웹 크롤링] 5. 선택자 (1) | 2022.05.12 |
| [웹 크롤링] 4. HTML 구조 (0) | 2022.05.09 |



