https://zzuzzu-99.tistory.com/2
[웹 크롤링] 8. 정적크롤링(3)
◆ 크롤링 대상 사이트 살펴보기 정적 크롤링은 주소값을 사용하기 때문에 한 페이지 내부에서만 원하는 데이터를 받아올 수 있다고 하였다. 하지만, 정적 크롤링에서도 페이지 이동과 유사한
zzuzzu-99.tistory.com
이 글을 바탕으로 네이버 주식 사이트에 있는 상하한가들의 종목,가격,전날대비 가격변동, 전날대비 가격등락 퍼센테이지 그리고 그 종목과 관련된 뉴스기사,일봉,주봉,월봉 이미지를 크롤링 하겠다.
#네이버 사이트를 이용한 크롤링은 상업적으로 사용하면 안됩니다.
네이버 금융
국내 해외 증시 지수, 시장지표, 뉴스, 증권사 리서치 등 제공
finance.naver.com
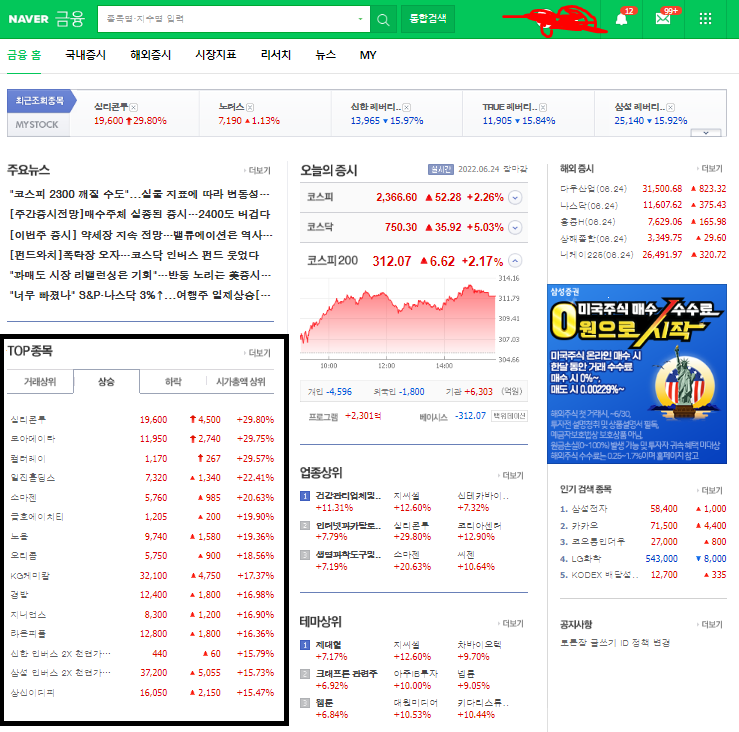
네이버 금융 페이지에서 저 박스 부분의 태그를 가져와야 한다.
f12를 눌러 검색창을 켜준다.
다음 select 버튼을 이용해 원하는 부분의 HTML태그를 검색해준다.
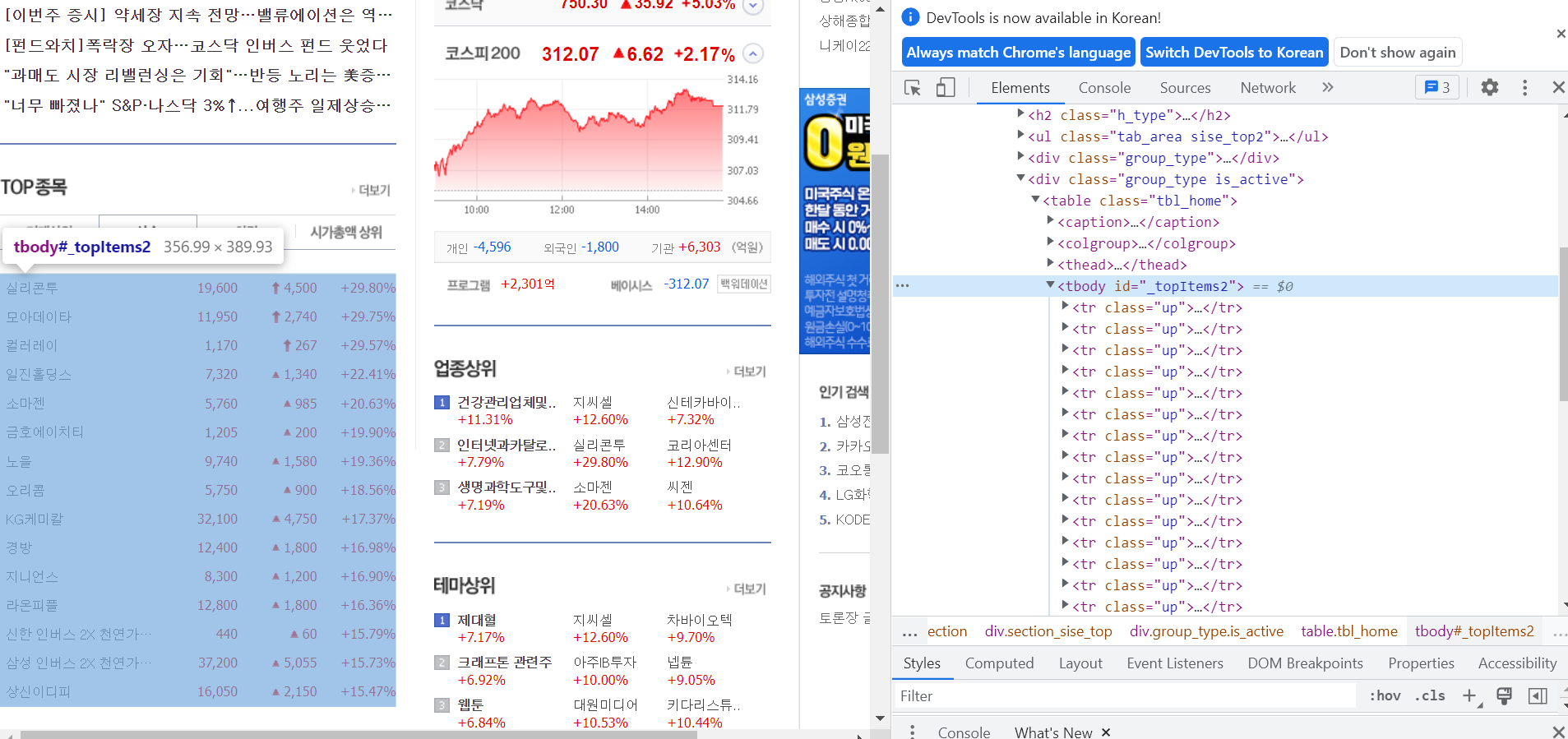
<tbody id = 'topItems2'> 이 부분이 내가 원하는 틀 부분이다.
이제 <tbody id = 'topItems2'> 안에 있는 <tr class ='up'> 부분들의 정보를 가져오면 된다.
1. 상한가 종목 감싸는 큰 틀 찾기
import requests
import re
from bs4 import BeautifulSoup
URL = 'https://finance.naver.com/'
raw = requests.get(URL)
html = BeautifulSoup(raw.text,'lxml')
units_up = html.select('#_topItems2>tr') # 오늘 상한가 종목들 전부 다 가져오는거이 글에서는 위 링크게시글과 달리 find 대신 select 함수를 이용해서 크롤링하였다.
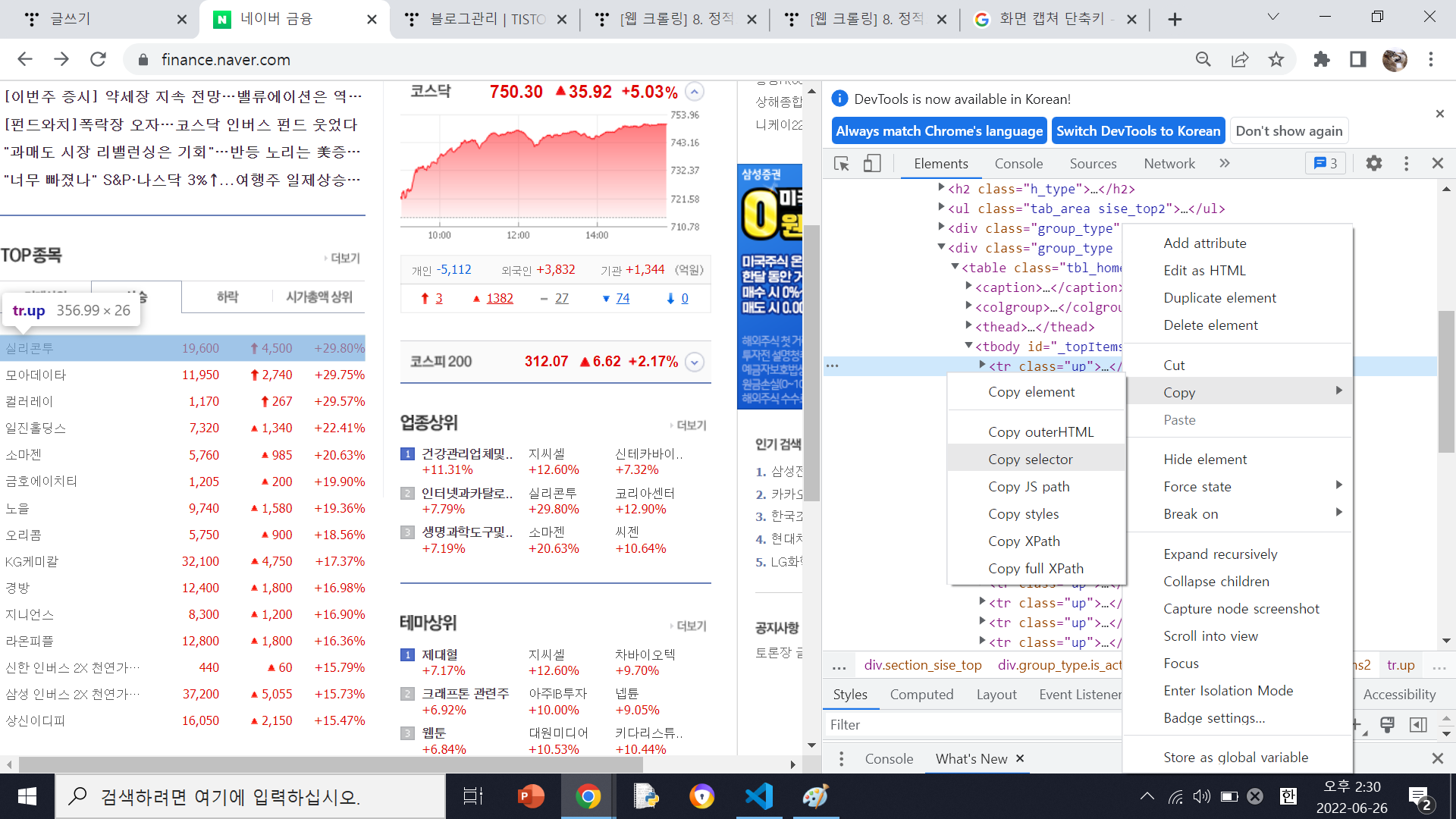
내가 사용할려는 태그의 마우스 오른쪽 누르고 copy에 들어가면 Copy selector를 누르면
#_topItems2 > tr:nth-child(1) 이 복사가 되는데 이것이 저 태그를 찾아들어가는 경로이다.
여기서 tr:nth-child(1) 여기서 숫자 부분은 첫번쨰 종목 두번쨰 종목 등을 나타내므로
#_topItems2 > tr 이 부분을 가져오면 큰 틀을 가저오게 된다.
2. 각 종목들의 정보 추출
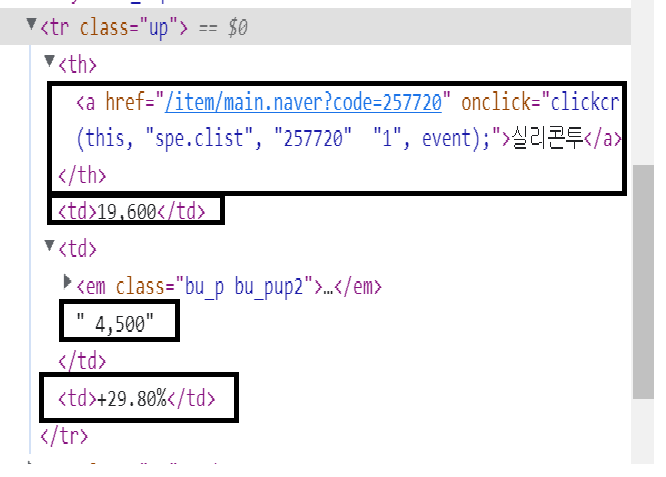
마찬가지로 종목들의 필요한 부분을 copy - copy selector 하면 각각
#_topItems2 > tr:nth-child(1) > th > a # 종목 이름
#_topItems2 > tr:nth-child(1) > td:nth-child(2) # 종목 가격
#_topItems2 > tr:nth-child(1) > td:nth-child(3) # 전날대비 가격등락
#_topItems2 > tr:nth-child(1) > td:nth-child(4) # 전날대비 가격등락 비율
이렇게 추출이 된다.
저 태그들을
#_topItems2 > tr > th > a
#_topItems2 > tr> td:nth-child(2)
#_topItems2 > tr > td:nth-child(3)
#_topItems2 > tr > td:nth-child(4)
이렇게 변경해주고 for문을 이용하면 각 종목들의 정보들이 나온다.
#코드
import requests
import re
from bs4 import BeautifulSoup
URL = 'https://finance.naver.com/'
raw = requests.get(URL)
html = BeautifulSoup(raw.text,'lxml')
units_up = html.select('#_topItems2>tr') # 오늘 상한가 종목들 전부 다 가져오는거
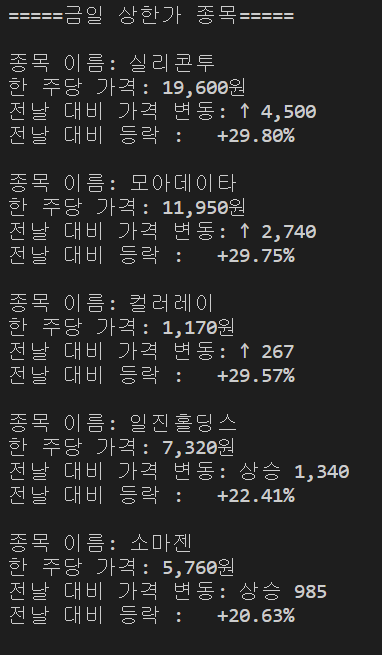
print('=====금일 상한가 종목=====')
print()
for unit in units_up[:5]:
title_up = unit.select_one('#_topItems2 > tr> th > a').text
price_up = unit.select_one('#_topItems2 > tr> td')
up = unit.select_one('#_topItems2 > tr > td:nth-child(3)').text
percent_up = unit.select_one('#_topItems2 > tr> td:nth-child(4)')
up = up.replace('상한가', '↑')
print('종목 이름:',title_up)
print('한 주당 가격:',price_up.text+'원')
print('전날 대비 가격 변동:',up)
print('전날 대비 등락 :',percent_up.text)# 출력결과
3. 뉴스기사 검색
네이버 검색창에 삼성전자, sk하이닉스 등을 검색해보면
https://search.naver.com/search.naver?where=news&sm=tab_jum&query=삼성전자 #삼성전자
https://search.naver.com/search.naver?where=sk하이닉스 # sk
이런식으로 URL패턴이 나오는걸 볼 수 있다.
이 패턴을 이용하여 뉴스기사를 웹크롤링 할 것이다.
title_up으로 종목이름을 가져왔기 때문에
news_up = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query='+title_up
raw2 = requests.get(news_up)
html2= BeautifulSoup(raw2.text,'lxml')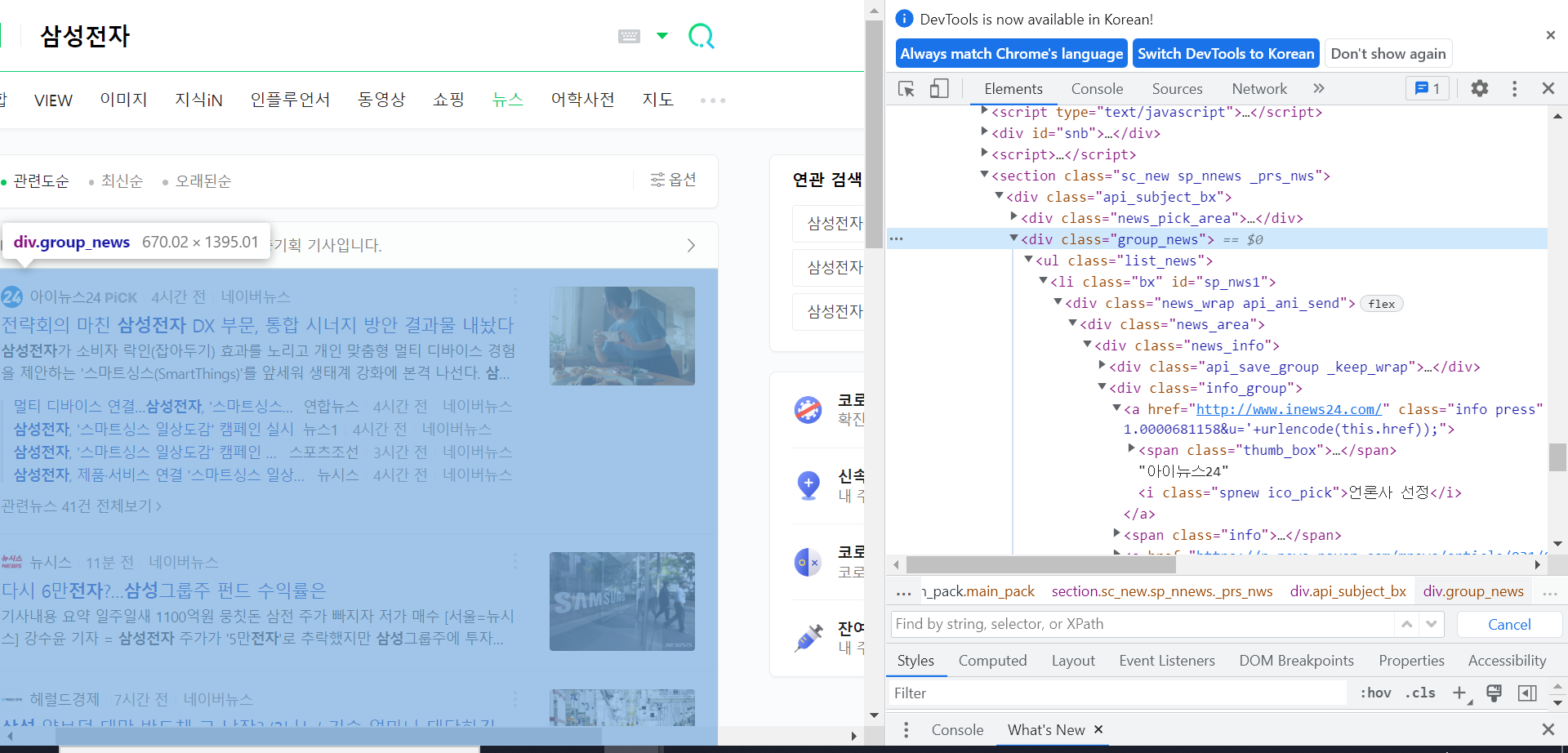
큰 틀 찾기 <div class='group_news>
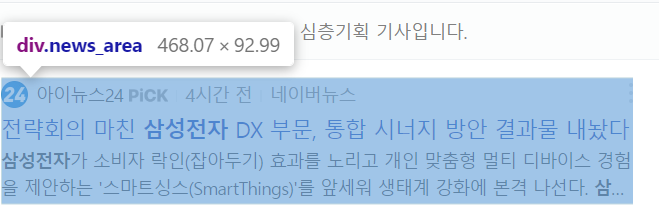
큰 틀 내에서 뉴스기사 찾기 <div class = 'news_area'>
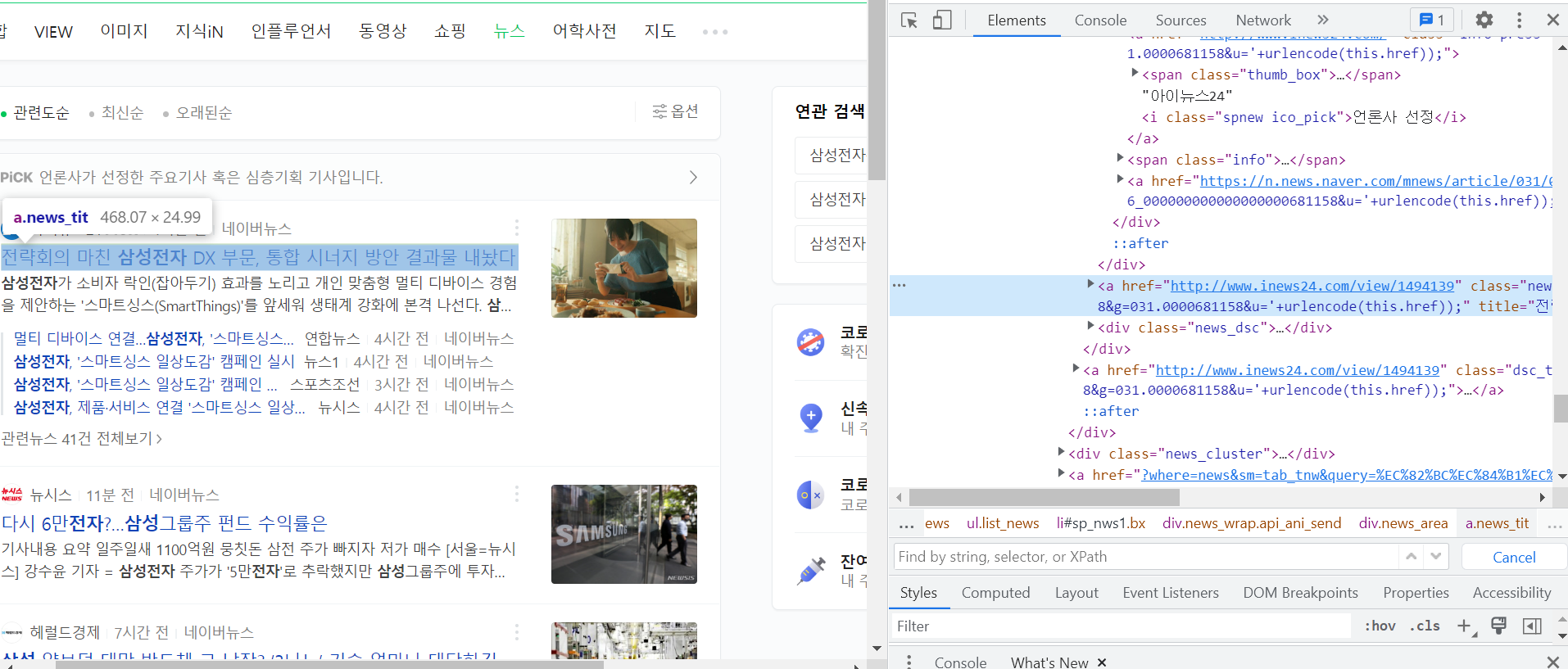
우리가 필요한 부분은 <div class='group_news> 이 태그 안에 있는 a.new_tit의 text부분만 'href'으로 정의되어 있는 링크 부분이다.
news_up = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query='+title_up
raw2 = requests.get(news_up)
html2= BeautifulSoup(raw2.text,'lxml')
news_up_box = html2.find('div',{'class':'group_news'})
news_up_list = news_up_box.find_all('div',{'class':'news_area'}) # 박스
for new in news_up_list[:3]:
new_title_up = new.find('a',{'class' : 'news_tit'})
print('뉴스 이름:',new_title_up.text)
link_up = new.find('a',{'class' : 'api_txt_lines dsc_txt_wrap'})
new_up = link_up['href']
print(new_up)
import requests
import re
from bs4 import BeautifulSoup
URL = 'https://finance.naver.com/'
raw = requests.get(URL)
html = BeautifulSoup(raw.text,'lxml')
units_up = html.select('#_topItems2>tr') # 오늘 상한가 종목들 전부 다 가져오는거
print('=====금일 상한가 종목=====')
print()
for unit in units_up[:5]:
title_up = unit.select_one('#_topItems2 > tr> th > a').text
price_up = unit.select_one('#_topItems2 > tr> td')
up = unit.select_one('#_topItems2 > tr > td:nth-child(3)').text
percent_up = unit.select_one('#_topItems2 > tr> td:nth-child(4)')
up = up.replace('상한가', '↑')
news_up = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query='+title_up
raw2 = requests.get(news_up)
html2= BeautifulSoup(raw2.text,'lxml')
news_up_box = html2.find('div',{'class':'group_news'})
news_up_list = news_up_box.find_all('div',{'class':'news_area'}) # 박스
print('종목 이름:',title_up)
print('한 주당 가격:',price_up.text+'원')
print('전날 대비 가격 변동:',up)
print('전날 대비 등락 :',percent_up.text)
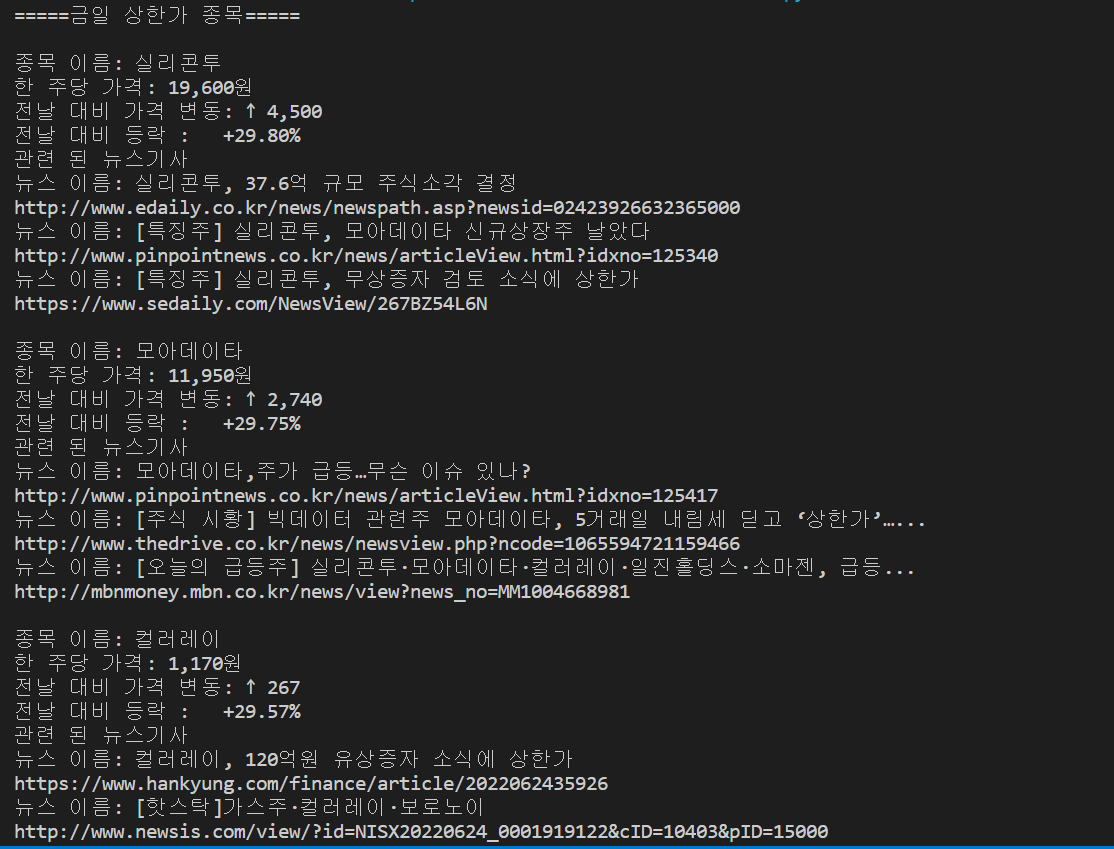
print('관련 된 뉴스기사')
for new in news_up_list[:3]:
new_title_up = new.find('a',{'class' : 'news_tit'})
print('뉴스 이름:',new_title_up.text)
link_up = new.find('a',{'class' : 'api_txt_lines dsc_txt_wrap'})
new_up = link_up['href']
print(new_up)
#출력결과
똑같은 방식으로 하한가도 하면 된다.
# 최종코드
import requests
import re
from bs4 import BeautifulSoup
URL = 'https://finance.naver.com/'
raw = requests.get(URL)
html = BeautifulSoup(raw.text,'lxml')
#box = html.find('tbody',{'id':'_topItems2'})
#units = box.find_all('tr',{'class':'up'}) # 박스
units_up = html.select('#_topItems2>tr') # 오늘 상한가 종목들 전부 다 가져오는거
print('=====금일 상한가 종목=====')
print()
for unit in units_up[:5]:
title_up = unit.select_one('#_topItems2 > tr> th > a').text
price_up = unit.select_one('#_topItems2 > tr> td')
up = unit.select_one('#_topItems2 > tr > td:nth-child(3)').text
percent_up = unit.select_one('#_topItems2 > tr> td:nth-child(4)')
up = up.replace('상한가', '↑')
news_up = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query='+title_up
raw2 = requests.get(news_up)
html2= BeautifulSoup(raw2.text,'lxml')
news_up_box = html2.find('div',{'class':'group_news'})
news_up_list = news_up_box.find_all('div',{'class':'news_area'}) # 박스
print('종목 이름:',title_up)
print('한 주당 가격:',price_up.text+'원')
print('전날 대비 가격 변동:',up)
print('전날 대비 등락 :',percent_up.text)
print('관련 된 뉴스기사')
for new in news_up_list[:3]:
new_title_up = new.find('a',{'class' : 'news_tit'})
print('뉴스 이름:',new_title_up.text)
link_up = new.find('a',{'class' : 'api_txt_lines dsc_txt_wrap'})
new_up = link_up['href']
print(new_up)
print()
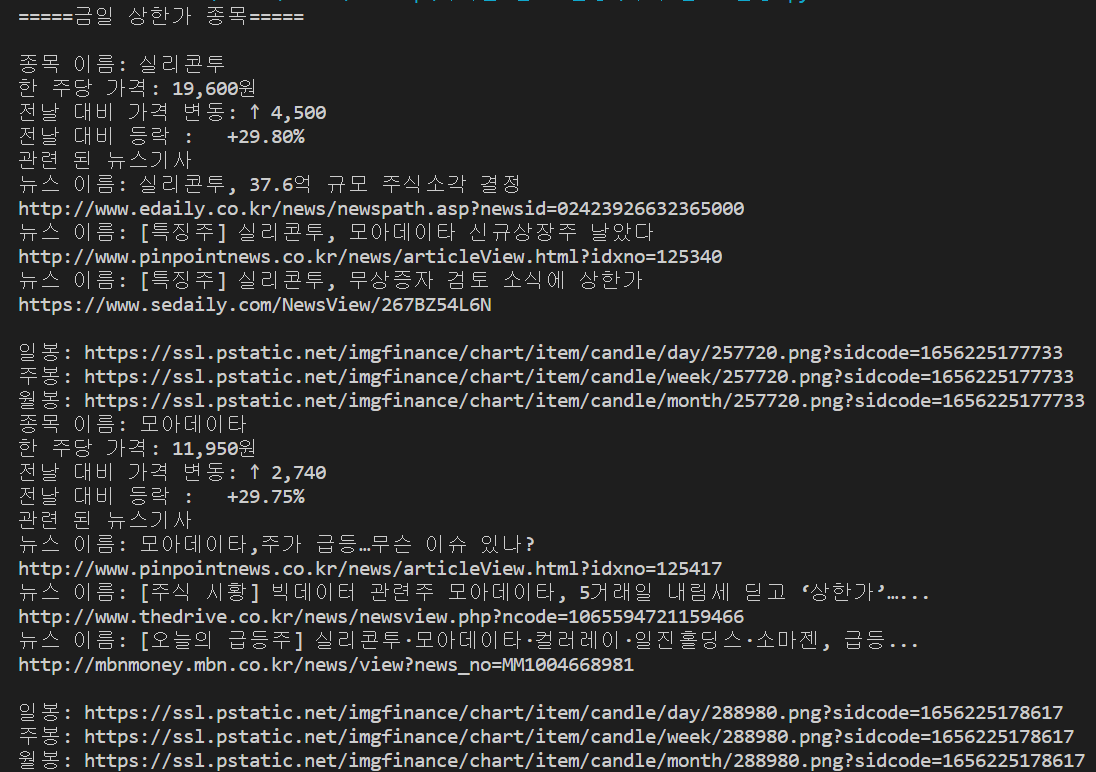
## 차트 가져오는 코드##
title_up = unit.select_one('#_topItems2 > tr> th > a')
chart_up_url = 'https://finance.naver.com'+title_up['href']
chart_up_raw = requests.get(chart_up_url)
chart_up_html = BeautifulSoup(chart_up_raw.text,'lxml')
chart_up = chart_up_html.select_one('#img_chart_area')
chart_up = chart_up['src']
chart_up_day = chart_up.replace('area','candle') #일봉
chart_up_week = chart_up_day.replace('day','week') #주봉
chart_up_month = chart_up_day.replace('day','month')#월봉
print('일봉:',chart_up_day)
print('주봉:',chart_up_week)
print('월봉:',chart_up_month)
print()
units_down = html.select('#_topItems3 > tr ')
print('====금일 하한가 종목====')
for unit in units_down[:5]:
title_down = unit.select_one('#_topItems3 > tr> th > a').text
price_down = unit.select_one('#_topItems3 > tr> td')
down = unit.select_one('#_topItems3 > tr > td:nth-child(3)').text
percent_down = unit.select_one('#_topItems3 > tr> td:nth-child(4)')
down = down.replace('상한가', '↓')
news_down = 'https://search.naver.com/search.naver?sm=tab_hty.top&where=news&query='+title_down
raw3 = requests.get(news_down)
html3 = BeautifulSoup(raw3.text,'lxml')
news_down_box = html3.find('div',{'class':'group_news'})
news_down_list = news_down_box.find_all('div',{'class':'news_area'})
print('종목 이름:' ,title_down)
print('한 주당 가격:',price_down.text+'원')
print('전날 대비 가격 변동:',down)
print('전날 대비 등락 :',percent_down.text)
print('관련된 뉴스기사')
for new in news_down_list[:3]:
new_title_down = new.find('a',{'class' : 'news_tit'})
print('뉴스 이름:', new_title_down.text)
link_down = new.find('a',{'class' : 'api_txt_lines dsc_txt_wrap'})
news_down = link_down['href']
print(news_down)
print()
## 차트 가져오는 코드##
title_down = unit.select_one('#_topItems3 > tr> th > a')
chart_down_url = 'https://finance.naver.com/'+title_down['href']
chart_down_raw = requests.get(chart_down_url)
chart_down_html = BeautifulSoup(chart_down_raw.text,'lxml')
chart_down = chart_down_html.select_one('#img_chart_area')
chart_down = chart_down['src']
chart_down_day = chart_down.replace('area','candle') #일봉
chart_down_week = chart_down_day.replace('day','week') #주봉
chart_down_month = chart_down_day.replace('day','month')#월봉
print('일봉:',chart_down_day)
print('주봉:',chart_down_week)
print('월봉:',chart_down_month)
print()#출력결과
'[python] > 웹 크롤링' 카테고리의 다른 글
| [웹 크롤링] 8. 정적크롤링(3) (0) | 2022.05.22 |
|---|---|
| [웹 크롤링] 7. 정적 크롤링(2) (0) | 2022.05.20 |
| [웹 크롤링] 6. 정적 크롤링(1) (0) | 2022.05.18 |
| [웹 크롤링] 5. 선택자 (1) | 2022.05.12 |
| [웹 크롤링] 4. HTML 구조 (0) | 2022.05.09 |



