◆ 크롤링 대상 사이트 살펴보기
정적 크롤링은 주소값을 사용하기 때문에 한 페이지 내부에서만 원하는 데이터를 받아올 수 있다고 하였다.
하지만, 정적 크롤링에서도 페이지 이동과 유사한 기능이 구현 가능하다.
그러기 위해서는 URL 주소값의 패턴을 파악해야한다.
COUPANG
쿠팡은 로켓배송
www.coupang.com
1. 상품검색
검색창에 마우스를 입력한다.

로또 번호와는 다르게, 검색값을 변경하면서 각 상품의 이름과 가격을 수집할 것이다.
2. 검색어의 URL 패턴 확인

검색했던 마우스가 URL 주소에 포함되어 있다.

이걸로 URL의 패턴을 알 수 있다.
url 주소
https://www.coupang.com/np/search?component=&q=마우스&channel=user
https://www.coupang.com/np/search?component=&q=모니터&channel=user
주소 값에서 component=&q=이라는 문구 뒤에 추가되는 문자열이, 바로 검색어가 되는 구조이다.
◆ 상품의 태그 및 선택자 확인
데이터 추출을 위해 각각의 태그와 선택자를 확인해야한다.
모든 데이터를 감싸는 큰 틀을 먼저 찾은 뒤,
그 틀에서 각각의 상품 데이터를 추출하고, 각각의 상품 데이터의 제목과 가격을 찾아준다.
1. 모든 데이터를 감싸는 틀
일단 모든 상품을 감싸고 있는 큰 태그를 찾는다.
(개발자 도구에서 select 버튼 활용)
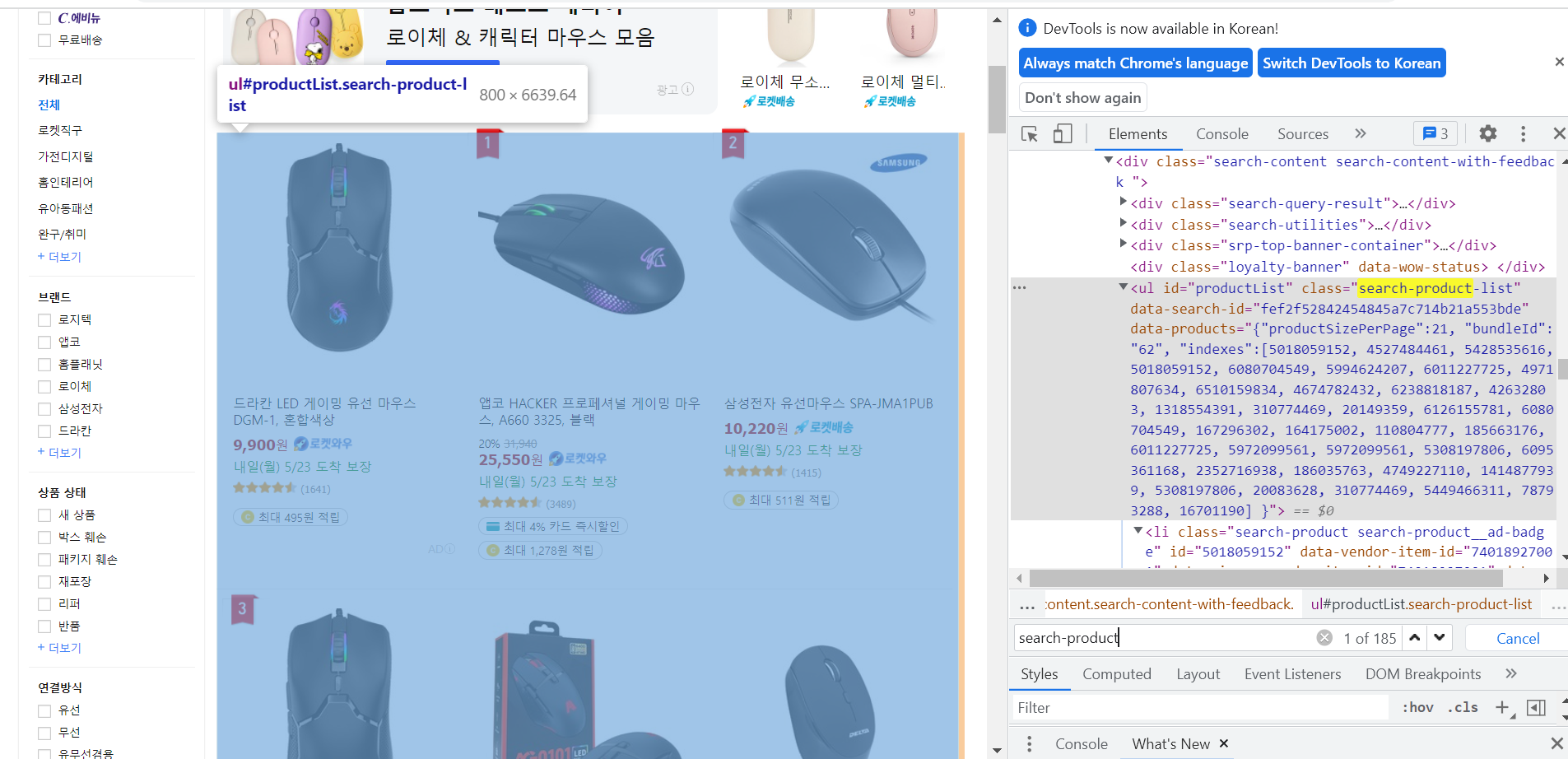
맨 위 상품부터 맨 아래 상품까지, 아래 태그가 모든 상품을 포함하고 있는 걸 확인가능하다.
하지만 여기서는 class만 선택자로 사용하면 안된다.
그 밑에 포함된 HTML의 다른 요소들도 동일한 클래스를 갖기 때문이다
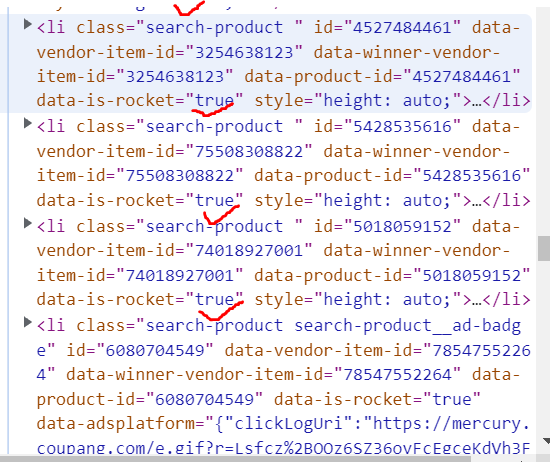
내가 원하는 틀만 전체 상품의 틀만 가져 오기 위해서는

내가 원하는 틀만 전체 상품의 틀만 가져 오기 위해서는
<ul id='productlist' class='search-product-list'> 이다.
2. 각 상품의 태그
이제 각 상품의 태그를 찾아온다.
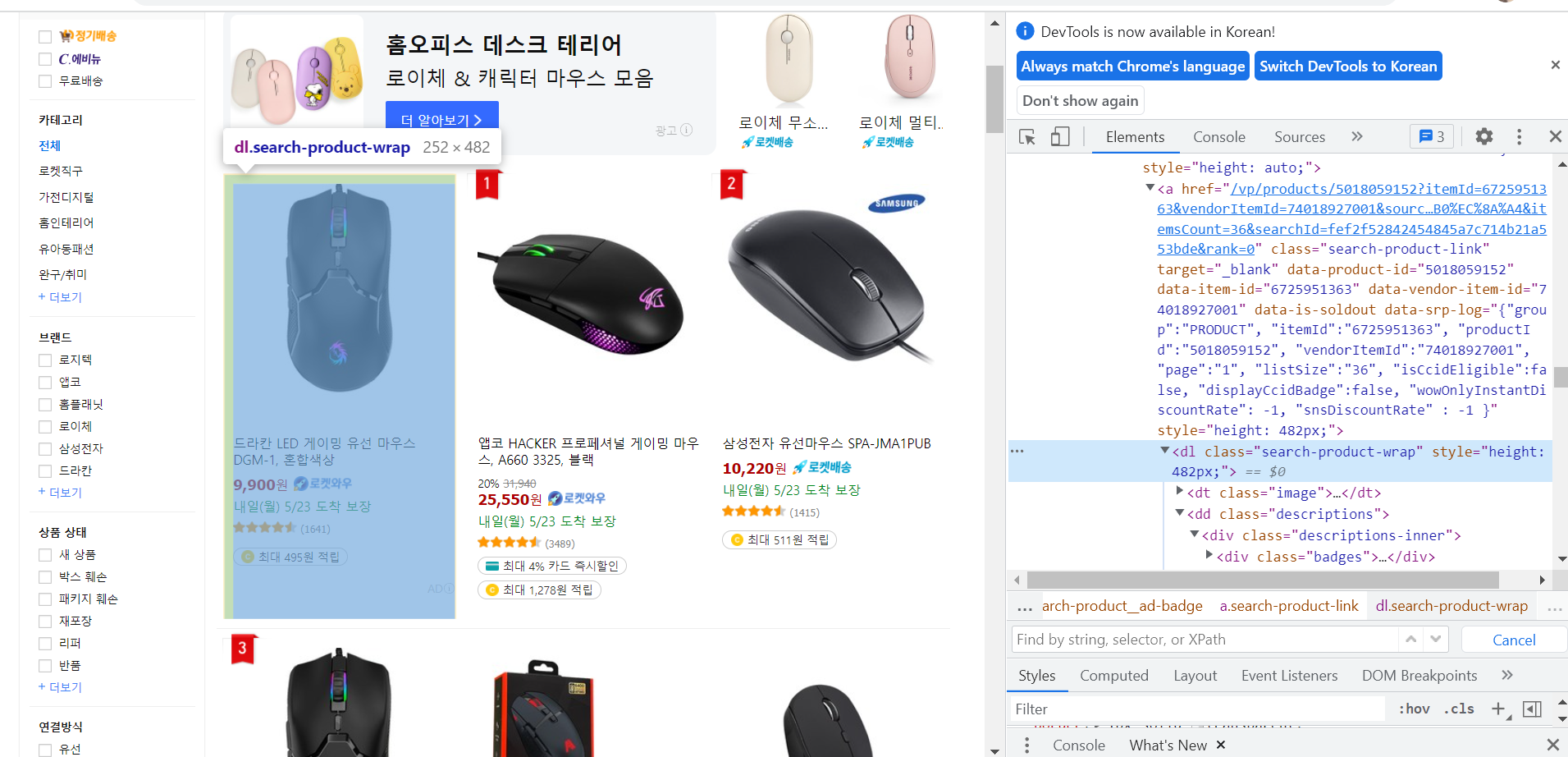
각 상품을 의미하는 태그 <dl class='search-product-wrap'>
각 상품의 이름과 가격도 마찬가지로, select 버튼을 사용해서 찾을 수 있다.
3. 각 상품의 제목과 가격
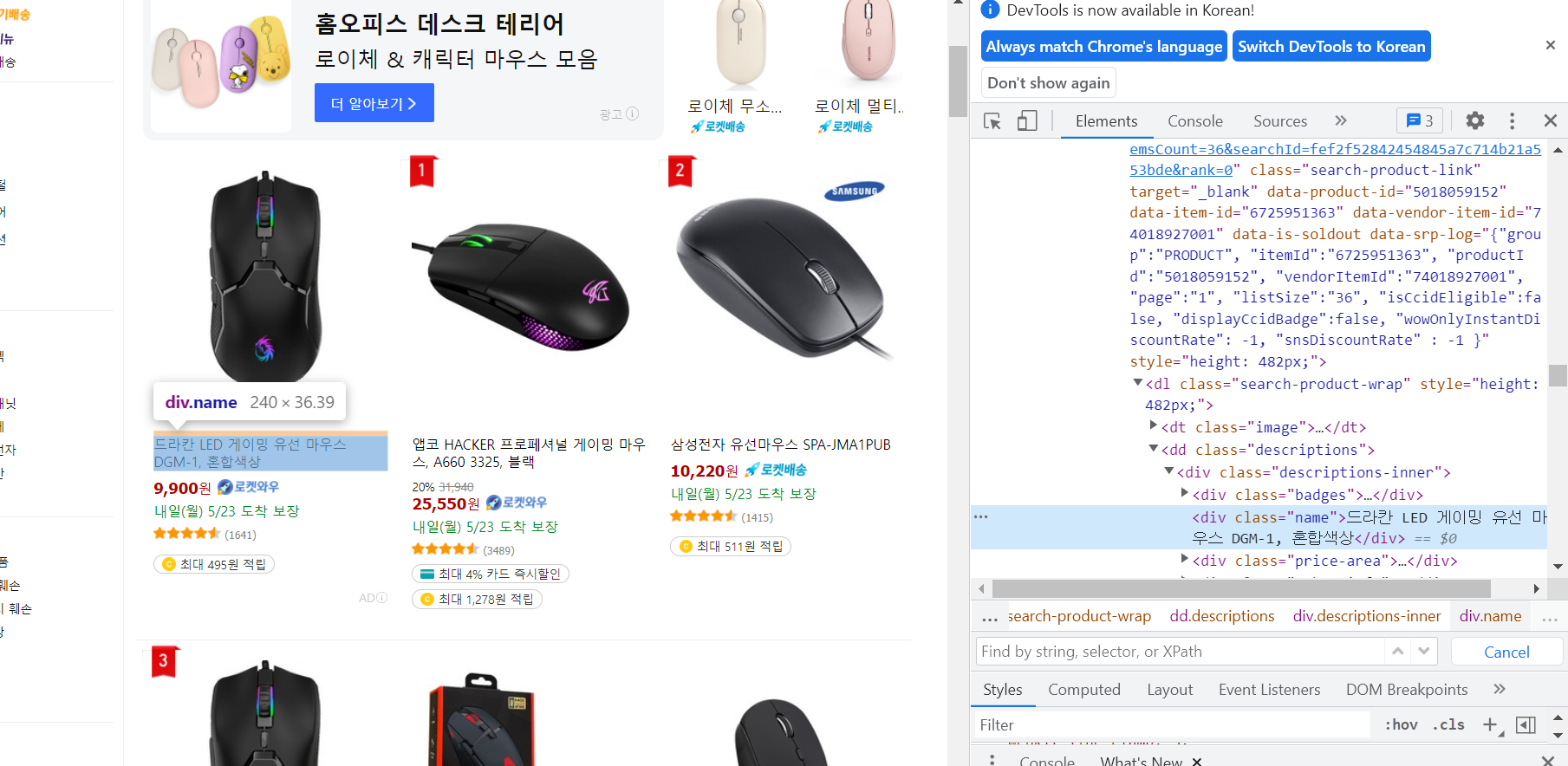

각 태그를 정리하면
이름 : <div class='name'>
가격 : <strong class='price-value'>
3. 포함관계 정리
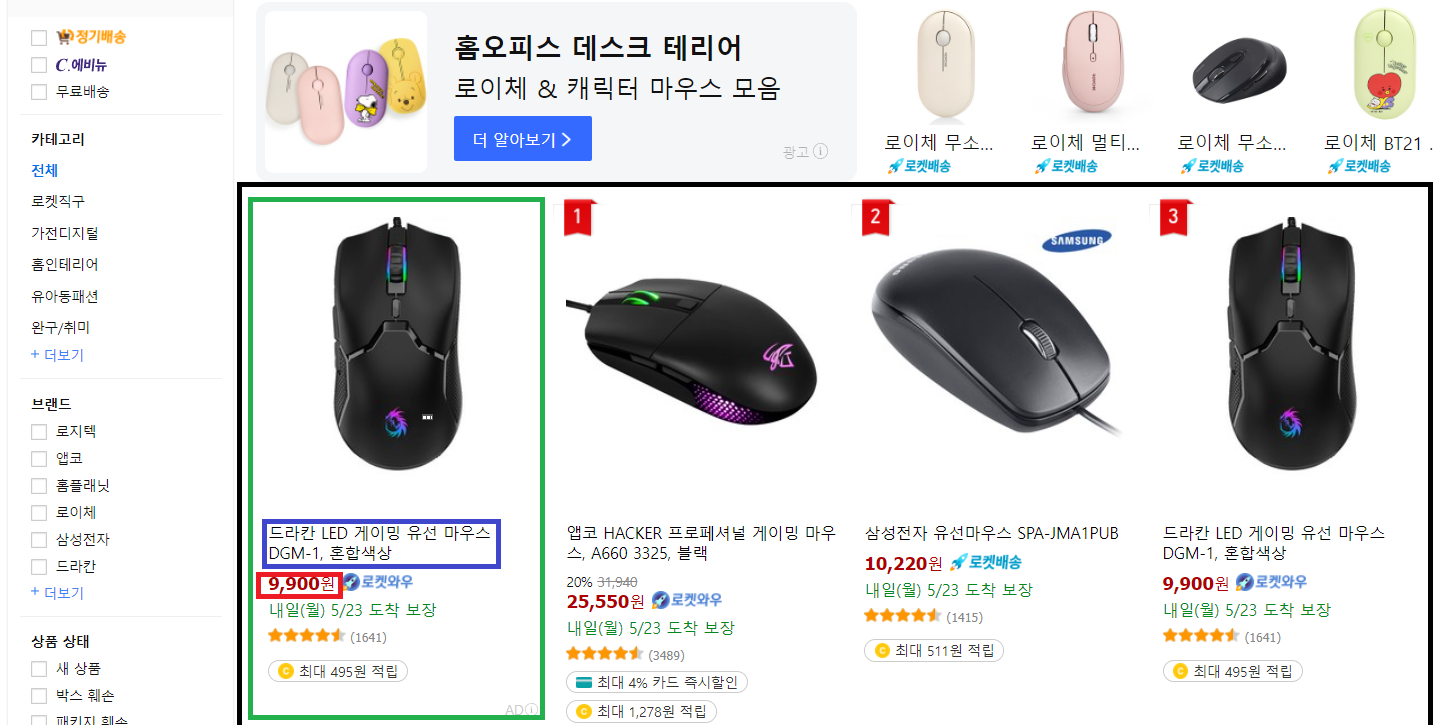
<ul id='productlist' class='search-product-list'>
<dl class='search-product-wrap'>
이름 : <div class='name'>
가격 : <strong class='price-value'>
사실 데이터를 추출할 떄 정답은 따로 없다.
find를 사용해 데이터를 감싸는 큰 틀을 먼저 추출할 수도 있고,
find_all을 사용해 바로 각 데이터를 추출할 수도 있다.
◆ 파이썬 코드 작성
url 주소의 패턴을 활용하여 여러 페이지의 정보를 수집해보겠다.
1. 라이브러리 불러오기
import requests
import bs42. url 주소 입력 및 HTML 받아오기
import requests
import bs4
URL = 'https://www.coupang.com/np/search?component=&q=마우스&channel=user'
raw = requests.get(URL)3. BeautifulSoup 클래스 객체 생성
BeautifulSoup 라이브러리를 활용하여 'raw.text'를 실제 HTML 코드로 변환해준다.
import requests
import bs4
URL = 'https://www.coupang.com/np/search?component=&q=마우스&channel=user'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
4 데이터를 감싸는 큰 틀 추출
앞서 찾은 큰 틀의 태그는 <ul id='productlist' class='search-product-list'> 였다.
html 변수에 저장된 HTML 코드에서 해당 태그와 선택자를 찾아서 box라는 변수에 저장한다.
import requests
import bs4
URL = 'https://www.coupang.com/np/search?component=&q=마우스&channel=user'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
box = html.find('ul',{'id':'productlist','class':'search-product-list'})5. 각 상품 추출
HTML 코드에서 큰 틀을 추출했으니 이제 각 상품의 데이터를 찾아야한다.
각 상품에 대한 태그는 <dl class='search-product-wrap'> 였다.
모든 데이터를 받아올 땐 find가 아닌 find_all 함수를 써야한다.
import requests
import bs4
URL = 'https://www.coupang.com/np/search?component=&q=마우스&channel=user'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
box = html.find('ul',{'id':'productlist','class':'search-product-list'})
items = box.find_all('dl',{'class':'search-product-wrap'})6. 각 상품의 이름과 가격을 추출
각 상품의 이름과 가격을 추출해 줄것이다.
items 변수는 리스트 형태이니 , for 구문을 사용하면 된다.
import requests
import bs4
URL = 'https://www.coupang.com/np/search?component=&q=마우스&channel=user'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text,'html.parser')
box = html.find('ul',{'id':'productlist','class':'search-product-list'})
items = box.find_all('dl',{'class':'search-product-wrap'})
for item in items[:10]:
title = item.find('div',{'class':'name'})
price = item.find('strong',{'class':'price_value'})
print('이름 :', title.text)
print('가격 :', price.text)
print()
# 추가로 쿠팡은 user_agent 지정을 하고 웹 크롤링을 진행 해 주어야한다.
https://blog.naver.com/kiddwannabe/221185808375
크롤링) 접속 차단되었을때 User-Agent지정(header)
User-Agent 자동 입력 및 자동 변경에 대해 살펴보실 분들은 아래 글을 봐주세요 (2020.08.27) 뭐야? 너 ...
blog.naver.com
★정리하기★
✔ BeautifulSoup 라이브러리를 사용하여 HTML 코드로 변환
✔ for문을 사용하여 여러 페이지의 데이터 수집
'[python] > 웹 크롤링' 카테고리의 다른 글
| [웹 크롤링] 네이버 주식 상하한가 종목 크롤링 (0) | 2022.06.26 |
|---|---|
| [웹 크롤링] 7. 정적 크롤링(2) (0) | 2022.05.20 |
| [웹 크롤링] 6. 정적 크롤링(1) (0) | 2022.05.18 |
| [웹 크롤링] 5. 선택자 (1) | 2022.05.12 |
| [웹 크롤링] 4. HTML 구조 (0) | 2022.05.09 |



